
在分析金融行业的投资数据时,经常会使用到平滑这个操作,下面记录了几种情形的实现与优化
所谓平滑
数据的平滑具体表现有多种情形,简单列举一下几种:
- 拉链表的数据一般没有连续的时间主键,只使用开始日期和结束日期来描述一个状态值(如评级)的生效日期范围,对拉链表做数据平滑就是把起期和止期展开成连续的时间,对应的状态和拉链表中所在时间区间一致
- 金融行业的交易数据,只有交易日才会有数据,非交易日无数据,所以时间主键会存在不连续的情况,需要把数据平滑成每一天都有,若无某一天的数据,则使用这个日期之前最近的数据
- 第三种区别于第二种情形,若一张表种的时间主键连续,即每一天都有数据,但是每条数据中有多个核心数值字段,且这些数值字段在某些日期为空,这些数值字段为空的规律不一致或没有规律,需要把数据平滑成核心数值字段都不为空的,若该字段为空,则取该日期之前最近的一个非空数据
以上几种情形,在做平滑时都会不可避免的用到笛卡尔积,下面是具体的案例,实现方式以及优化措施
- 文末提供了生成虚拟数据的python脚本
- 更具体的代码见Tiankx1003/TechSummary
- 若是有更优的实现方式,欢迎在评论区或issues交流
一、拉链表的展开
第一种情形比较简单,只需要使用拉链表和日历表做笛卡尔积就行
生成一张日历表
create table if not exists num (i int);-- 创建一个表用来储存0-9的数字 |
然后做一张拉链表, 建表语句如下
create table rating_info_zip( |
我们需要得到一张展开成连续日期的表,建表语句如下
create table rating_info_unzip( |
这种情况实现方式就很简单,只需要和日历表做笛卡尔积,然后取出对应时间区间的数据就好
insert overwrite table rating_info_unzip |
上面这种实现方式简单直接,但是性能较差,如果t1有m条数据,t2有n条数据,那么发散后就是m*n
后面我们再说优化思路
二、平滑生成非交易日数据
先做一张交易表,建表语句如下
create table trade_info( |
数据特征如下图,交易日有数据,非交易日无数据,平滑即复制出一条数据和最近的一条交易日数据一致
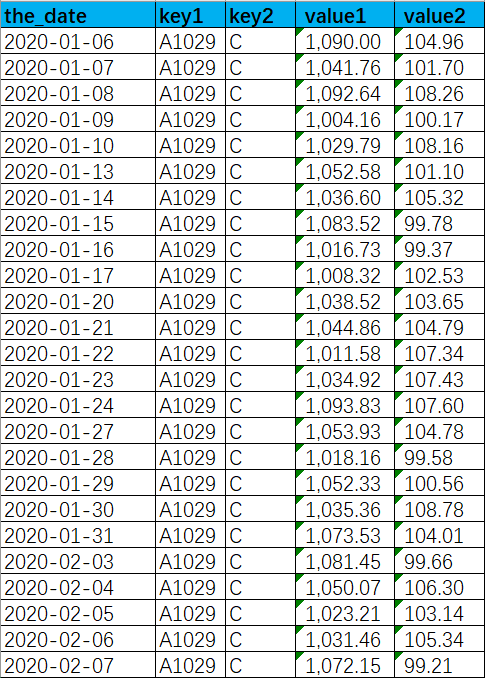
图中以某一组主键为例key1='A1029' and key2='C',能看出只有工作日有数据,需要平滑成下图的效果
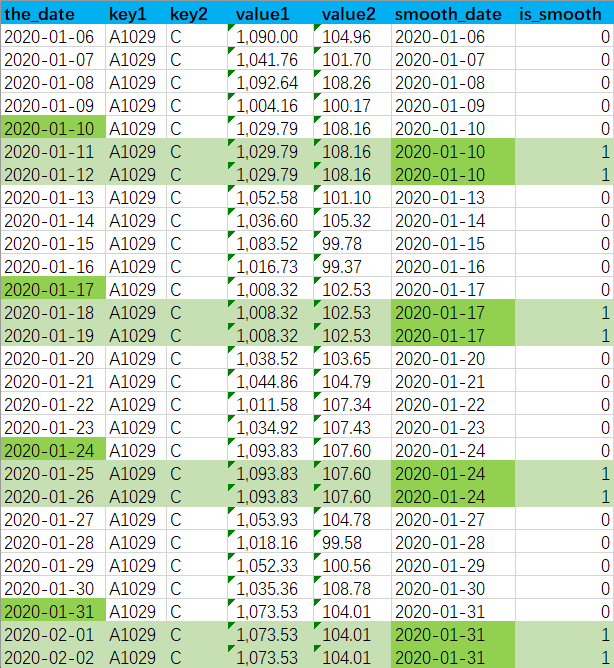
smooth_date用于表示平滑取自的日期,如周六和周日都是从周五平滑下来的,那他们的smooth_date都是周五的日期is_smooth用于表示该条数据是否是平滑生成的,1为是,0为否,- 对于非平滑数据
is_smooth='1',smooth_date和the_date一致
最后平滑后的目标表建表语句如下
create table trade_info_smooth( |
实现逻辑如下
-- 第一步先开窗取出每条数据对应的下一个有数据的日期 |
两种优化思路
笛卡尔积时左表的每条数据都要发散成n(右表的条数)倍,性能很差,我们可以采用下面两种方式优化
1.是否跨年区分处理
对于start_date和end_date在同一年的数据我们没必要发散到整张表,只需要和所在年的365天发散即可
非交易日跨年的情况占少数,所以这种优化方式对效率提升了大约n/365倍
- 不需要平滑的数据即
start_date = end_date,可以直接取
以trade_info_smooth为例,实现方式如下
insert overwrite table trade_info_smooth |
- 当然你也可以区别跨月处理,但是性能不如跨年
2.打散左表,扩容右表
在做笛卡尔积时,同一个key会进到一个reducer种进行处理
如果存在数据倾斜,key值会有聚集
我们可以把左表的key打散,与扩容后的右表通过虚拟主键关联
既可以提升并发度,又可以解决数据倾斜问题
以trade_info_smooth为例,实现方式如下
set mapred.reduce.tasks=20; -- 根据打散和扩容程度设置reducer个数 |
- reduer个数,打散倍数,扩容倍数,三者一致
三、对于核心数值为空的填充
我们先造一张扩展的交易表, 建表语句如下
create table trade_info_ext( |
数据特征如下下图,
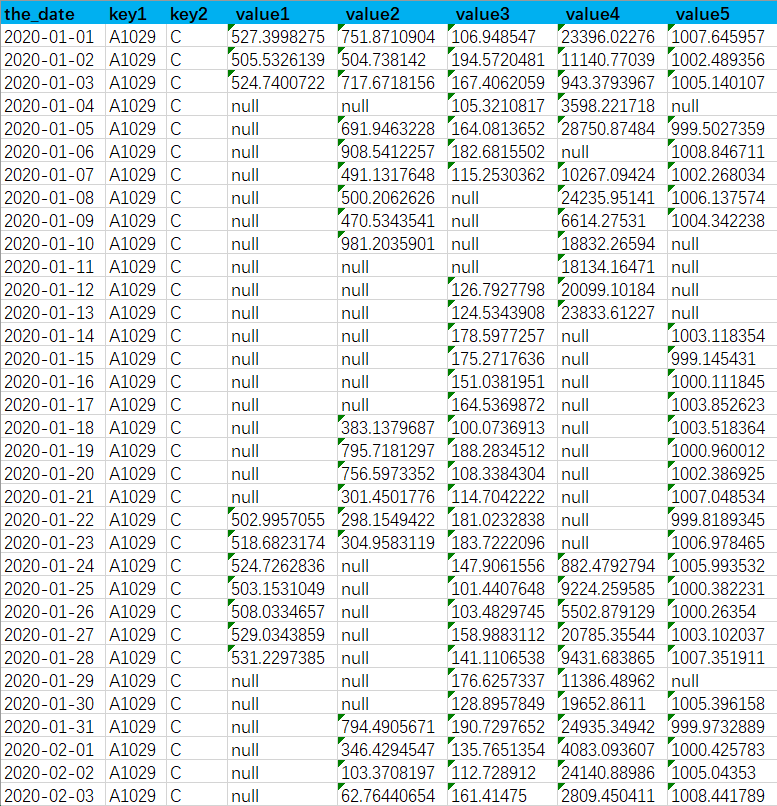
图中以某一组主键为例key1='A1029' and key2='C',有更多的数值字段,从图中能看出日期主键连续,但是每个数值字段都有为空的情况,需要给为空的的值填充一个该日期之前最近的一个非空值,最终效果如下图
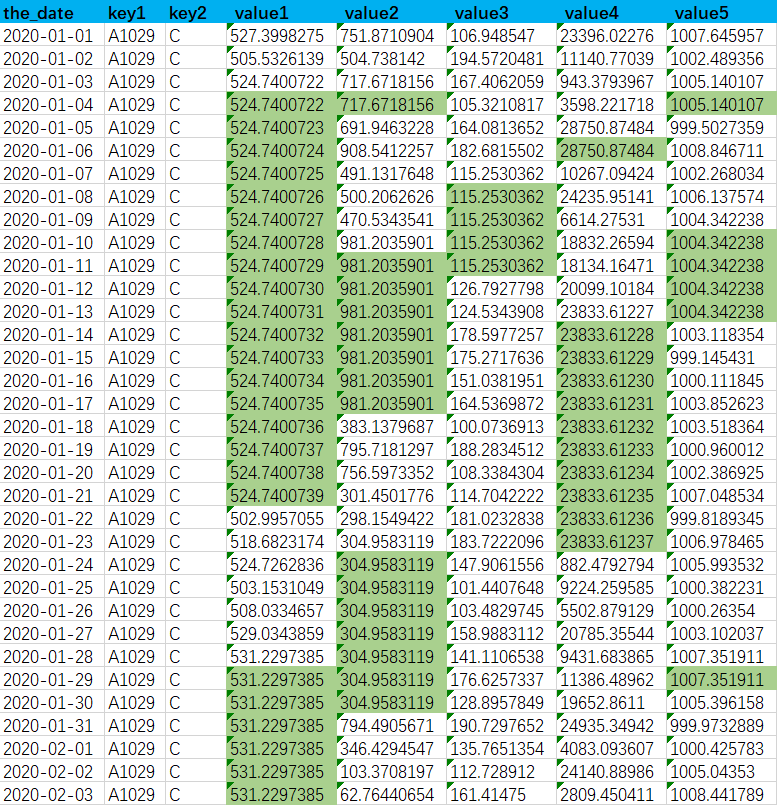
表中这些数值字段为空的日期并不存在一致的规律,或者根本就没有规律
所以同一天的两个空值字段可能取自不同的日期
- 暂且不关心每个空值转换取自的日期
smooth_date和is_smooth
Oracle数据库支持lag(col ignore nulls)
insert overwrite table trade_info_ext_smooth |
而hive并没有改语法的支持如果针对每个数值字段参考trade_info_smooth的方式处理,然后再通过主键关联在一起
代码如下
-- 很长,很蠢, |
这种实现方式代码逻辑很臃肿,而且效率非常低,时间复杂度提升了n(需要平滑的value字段个数)倍
其实我们可以借助collect_list或者collent_set的自动去重特性来间接实现ignore nulls
实现方式如下
select the_date |
写在最后
其实上面这些情形是在同一个需求中遇到的,
即trade_info_ext表同时存在非交易日无数据和有数据但数值字段为空的情形
需要先针对数值字段补充空值,然后在针对日期做平滑处理
最初的处理方式是在Sqoop接数据时就完成第一步的逻辑
因为是从上游Oracle数据库接入数据,所以可以使用lag(col ignore nulls)
接入数据后在关联日历表做日期平滑
但是数据量过大时容易拖垮上游数据库性能,使用Hive分布式处理更合适
所以才有了上述的优化
- 区分跨年处理
- 打散左表扩容右表增加并发度
- hive实现
ignore nulls
最终实现
环境信息
- CentOS 7.5
- hadoop-3.1.3
- hive-3.1.2 execution-engine spark-2.4.5
- python-3.6.8
- jdk1.8.0_144
- scala-2.11.8
insert overwrite table tmp_trade_info_ext_smooth |
虚拟数据生成脚本
import datetime |
鸣谢
- 感谢书犁长久以来对我工作的帮助与支持

